Migration Plan: Obsrv GA to Obsrv 1.0
This document outlines the migration strategy from Obsrv GA to Obsrv 1.0, with a focus on data integrity, minimal downtime, and operational continuity.
Overview
Section titled “Overview”This document outlines the migration strategy from Obsrv GA to Obsrv 1.0, with a focus on data integrity, minimal downtime, and operational continuity.
Migration Timeline & Activities
Section titled “Migration Timeline & Activities”The following visual captures the phased migration activities and associated timelines:
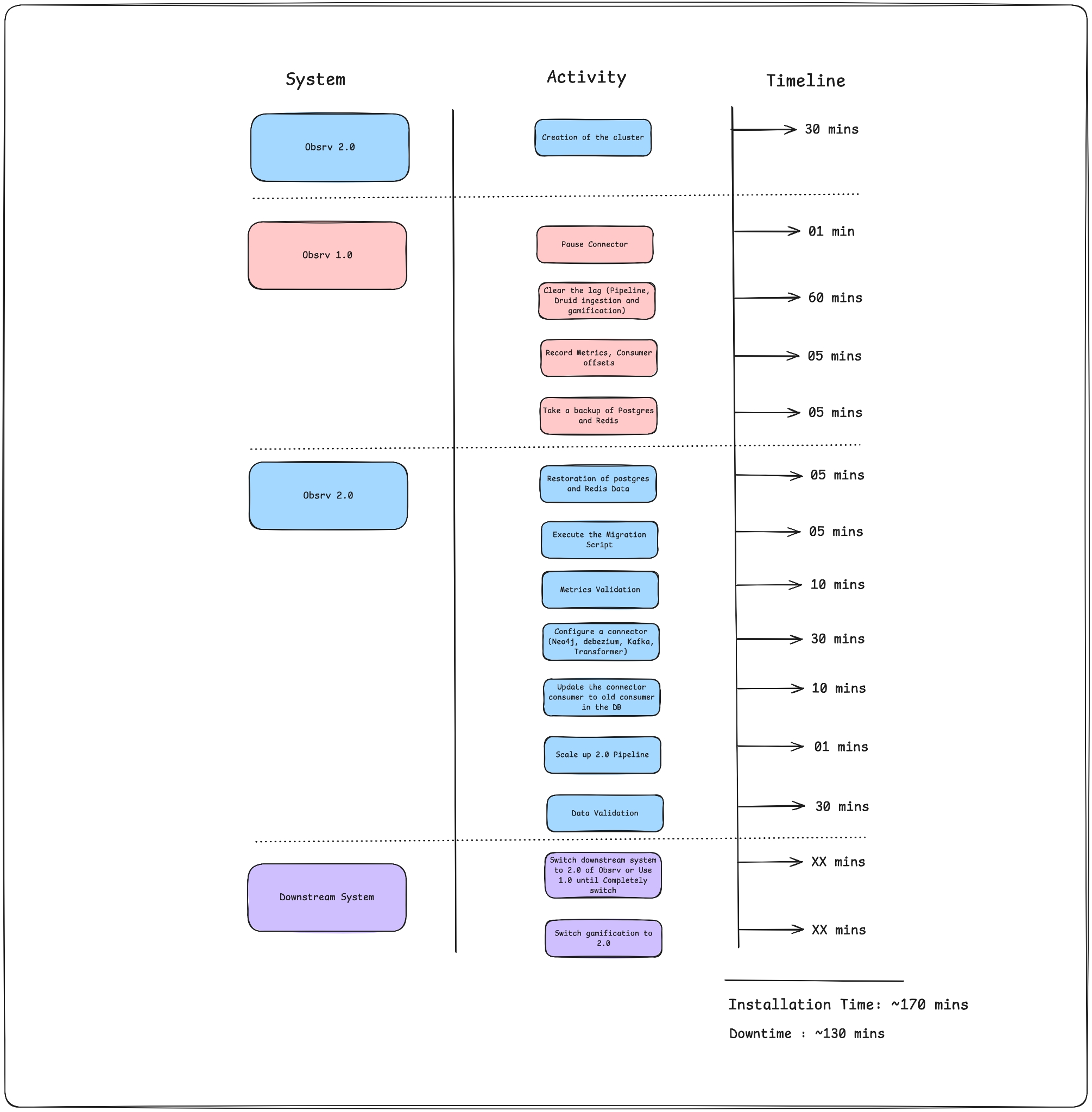
Step-by-Step Migration Process
Section titled “Step-by-Step Migration Process”1. Provision Obsrv 1.0 Cluster
Section titled “1. Provision Obsrv 1.0 Cluster”- Deploy a dedicated Obsrv 1.0 cluster.
- Ensure isolation from live traffic during setup and validation.
2. Configure Backup Paths
Section titled “2. Configure Backup Paths”Update Obsrv 1.0 to point to existing GA backup locations:
- Druid: Reuse GA S3 backup path.
- Secor: Reuse GA S3 backup path.
- Velero: Reuse GA S3 backup path.
3. Disable Ingestion in Obsrv 1.0
Section titled “3. Disable Ingestion in Obsrv 1.0”- Temporarily disable all ingestion pipelines to prevent data writes during migration.
4. Decommission Obsrv GA Ingestion
Section titled “4. Decommission Obsrv GA Ingestion”a. Infosys Transformer
- Scale down the transformer job.
- Record current consumer group offsets.
b. Connectors
- Scale down GA connectors: Kafka, Debezium, and Neo4j.
- Capture consumer group offsets per partition for each.
5. Resolve Pipeline Backlogs
Section titled “5. Resolve Pipeline Backlogs”- Ensure all pipelines in GA are fully drained.
- Specifically, clear:
- Secor lags
- Druid ingestion lags
- Temporarily scale infra, if needed, for quicker lag resolution.
6. Suspend the GA supervisors
Section titled “6. Suspend the GA supervisors”- Suspend all the running Druid supervisors to prevent conflicts with PostgreSQL backup and restore records.
7. Trigger Final Backups
Section titled “7. Trigger Final Backups”- Run manual backups for Postgres and Redis after pipeline clearance.
- Confirm successful sync to S3.
8. Restore & Migrate Core Data
Section titled “8. Restore & Migrate Core Data”a. Postgres
To restore and migrate obsrv GA data, follow these steps:
- Disable Postgres Migration Scripts: Before initiating Obsrv 1.0 installation, disable Postgres migration scripts V4 and V5 of the obsrv database.
- Installation and Data Migration: Proceed with the Obsrv 1.0 installation. Perform the PostgreSQL data restoration and verify.
- Enable and Run Migration Scripts: After the Postgresql data restoration is complete, re-enable Postgres migration scripts V4 and V5. Execute the PostgreSQL migration bundle to migrate data to the 1.0 format.
b. Redis
- Restore Redis snapshot and convert to the 1.0-compatible format.
c. Schema Transformation
- Execute the schema migration automation to convert all legacy table formats.
9. Validate Migrated Data
Section titled “9. Validate Migrated Data”- Verify dataset visibility via the Obsrv 1.0 console.
- Confirm API-level queryability.
- Ensure all Druid supervisors are healthy and running.
10. Reinitialize Supervisors
Section titled “10. Reinitialize Supervisors”- Re-run the ingestion Helm task to create the
system eventsdatasource. - Suspend and resume all supervisors through the Druid console.
11. Reconfigure Connectors in Obsrv 1.0
Section titled “11. Reconfigure Connectors in Obsrv 1.0”Update each connector to resume from the last committed GA offset:
- Kafka, Neo4j, Debezium
- Infosys Transformer (via automation script)
Update respective consumer group details in the 1.0 configuration.
12. Republish Datasets
Section titled “12. Republish Datasets”- Republish all datasets, adhering to the 1.0 schema structure.
13. Scale Up Obsrv 1.0
Section titled “13. Scale Up Obsrv 1.0”- Bring ingestion pipelines and connectors back online.
- Begin real-time ingestion and processing.
Post-Migration Validation
Section titled “Post-Migration Validation”- Monitor end-to-end ingestion in 1.0.
- Validate:
- Data availability
- API and query response integrity
- Consumer group offset correctness
- System performance and stability
Final Cutover
Section titled “Final Cutover”Once confidence is established:
- Redirect all downstream consumers to Obsrv 1.0 APIs.
- Retire remaining Obsrv GA components gracefully.